I started my journey about 2 years ago and submitted my first paper as a first author near a week ago. I believe if you have the proper background, start today without giving up, you are eventually going to make it work. But the question here is how to survive. Besides the mental aspects and the original research idea, there is equally, if not even more important facet of this road. That is productivity, your tools, and your workflow.
Moreover, if you live in a developing country, the computation resources are probably scarce even if you’re working at a labaratory. Lab students are lovely people but considering that you’re a noobie undergraduate researcher, you’ll have to wait much longer in the queue to use limited computational resources.
In this series of articles, I’ll show you how I overcame these obstacles and made it to the end. I’ll share the workarounds, free resources, tools, and methods that could help you in your research project.
The key to improving your productivity is that you have to have a well-defined, efficient workflow for experimenting. Having an effective pipeline will enable you to quickly prototype and evaluate your ideas. I think as a researcher, you should always be either debugging your model or looking for new ideas; The last thing you want to do is struggle with your code or scripts, since we all know how depressing “tensor shape debugging” is.
The Pipeline
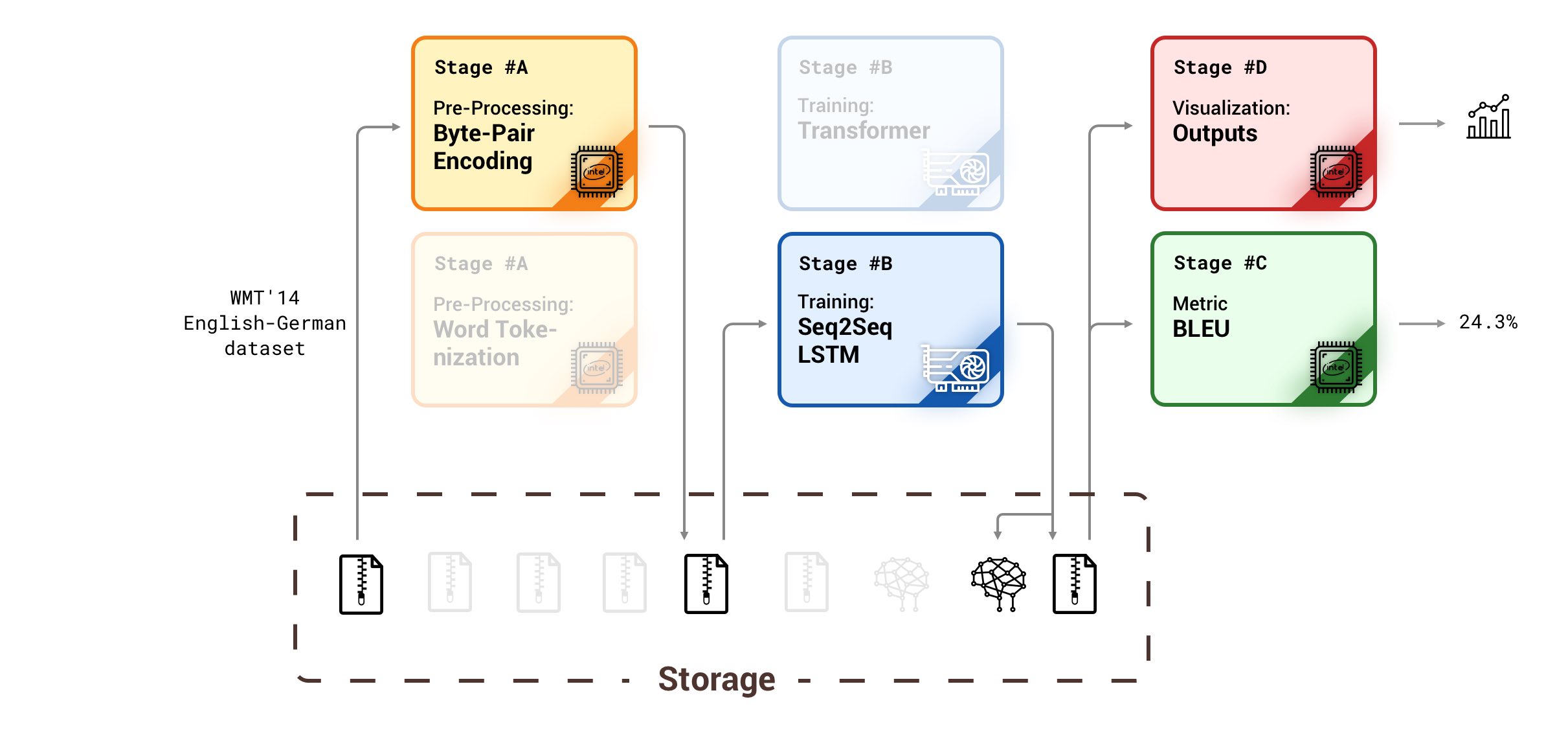 Figure 1 - This figure illustrates an example of experimenting pipeline in Machine Translation research.
Figure 1 - This figure illustrates an example of experimenting pipeline in Machine Translation research.
The pipeline in research is defined as a set of stages which starts from raw data and ends with a quantifiable value. Each of these steps is runnable blocks which acquire data as an input, producing an output (Maybe in another kind) as a result of computation. e.g., The dataset pre-processing, The model training, The metric calculation, and etc. Additionally, they should be easily replacable with their counterparts. So that you can change the dataset or metric as effortless as changing one line of code.
To implement a pipeline we need 3 essential parts:
- API: A set of rules which defines the input/output protocol of each stage. Well-defined API here is the key to swappable components.
- Storage: We need a stateless pipeline in order to run the stages anytime anywhere. To achieve that, we need to save each stage’s output on persistent storage, thus the next stage could continue the pipeline without a need to recalculate the previous ones.
- Computational Resources: To run each stage, surely we do need computational resources (often GPUs). Since rapid prototyping is vital to a research project, we need to have multiple independent jobs running simultaneously. This means that running a single stage must not block the others.
In the following sections, I will describe these parts in advanced detail. In the end, we will have an efficient distributed pipeline which is wholly made of [almost] free available resources capable of running multiple parallel and fast-performing tasks.
API
By the API, I simply mean the format you use to represent your data. You may want to represent your data in binary form, or pure text. You may want to use JSON or XML to give your data a structure. The API really depends on your task and your preference. You should go with what you like and you’re comfortable with. But I will give you some should and shouldn’ts that came from my experiences in the last two years.
Do not use JSON, XML, PICKLE, or any other structured protocols. Instead, stick with the raw files and use directories to give them bare minimum structure.
Using JSON or other similar formats has two downsides. 1) They are not as readable as raw text 2) Generally, datasets in Deep Learning are massive in size. Reading a JSON file with over 1M data points can quickly exhaust your RAM given the fact that free computational resources are pretty restricted, specially with the RAM at hand. Using a raw text format will enable you to read massive files line by line, and yet use small amount of memory.
[
{
"src":"Czechs qualified for EURO .",
"tgt":"Die Tschechen qualifizierten sich für EURO ."
},
{
"src":"But that was not until Sunday .",
"tgt":"Aber das erst am Sonntag ."
},
...
]
Czechs qualified for EURO . Die Tschechen qualifizierten sich für EURO . But that was not until Sunday . Aber das erst am Sonntag . ...
Figure 2 - Structured file vs. raw text format.
Take the machine translation research as an example. Every data point in the dataset contains two sentences: the source and the target. One could represent such dataset using the JSON format (Figure 2). Now let’s store it using tab-separated files (.tsv). Each line consists of the source sentence, the tab, and the target. Now compare this to the JSON one. Isn’t it easier to read for both human and software? Imagine how much space you could save by using the TSV format.
Finally, do not leave the files uncompressed. As we’re using free stuff, we need to keep space-saving in our minds. Compress the stage’s output before saving it on the storage. Pick either the bzip2 or gzip format (not a mixed bag) and stick to it through your research.
Storage
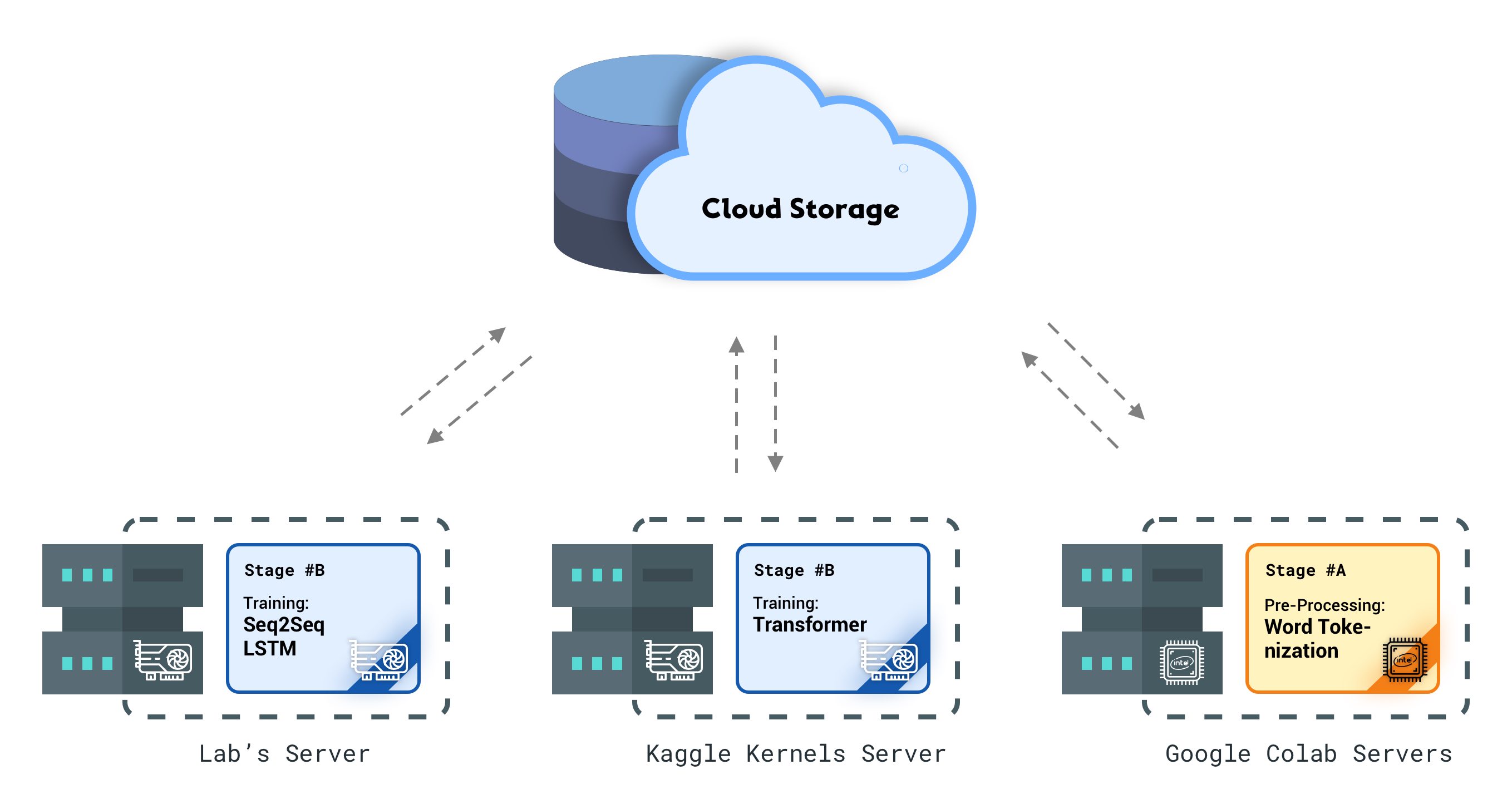 Figure 3 - We can run multiple stages of our pipeline at the same time by having persistent global storage.
Figure 3 - We can run multiple stages of our pipeline at the same time by having persistent global storage.
Global persistent storage is a crucial part of our pipeline since we continually read and write stages’ outputs from and to the storage. Not only this global storage helps us save the stage’s results, but also it is a place to keep the model’s checkpoints.
Having consistent global storage will enable us to see servers as disposable computational resources. How? Select your desired pipeline stage, connect it to a VM, train your model, save the result on the global storage, and remove the VM. That’s it.
Was your training interrupted due to lack of resources? No problem. The last checkpoint is on the global storage. Connect your stage to another platform and resume your training! Fancier GPUs in your lab suddenly became available? That’s Okay! stop the training, connect the current stage to your lab’s server and you’re good to go!
So what is this global storage thing? What makes it so important? Actually, I was referring to cloud object storage services. If you’re not familiar with them, think of Google Drive but with no space limitation (pay-as-you-go pricing model) and no UI or collaborative stuff. Cloud storages are just disks in the cloud with web service interfaces to store and retrieve the data. They also provide cheap pay-as-you-go pricing models in contrast to Google Drive, which offers storage-space based pricing.
There are several cloud storage providers, however, as Tensorflow/Keras only supports S3 and Google Cloud APIs, we should look for services which support at least one of them. I’ve gathered a list of cloud storage providers which i personally prefer:
-
Amazon S3 (non free): Amazon is probably the oldest and most popular cloud storage provider. However, their free plan only gives you 5 GB to go. It might be suitable for testing purposes but obviously is useless for our case. If you’re okay to pay for it, don’t do it yet. I have better ones in the next items.
-
Google Cloud Storage (Almost Free): Google is also one of the best cloud providers. They will give you 300$ free credits immediately after the sign-up (needs a valid credit card though). You can spend this credit on their thousand of services. Since cloud storage’s price is pretty low, the initial credit can easily back you up for a couple of months. Caution: Do not spend money on Google cloud GPUs, you can use them free. I’ll explain it in the next section.
-
Microsoft Azure (Free): Unfortunately, Azure does not offer S3 compatible cloud storage. They have their own blob storage option which neither of deep learning frameworks supports (typical Microsoft). However, with a couple of tricks and flicks, we can make it work. There is an open-source software called Minio which exposes S3 compatible API on top of almost any raw storage. Luckily they have a ready-to-use solution to provide the S3 compatible API on top of Microsoft in-house object storage service. The downside of this method is that you need a separate VM to run the Minio software. Good news is that the Minio is rather lightweight and the VM cost could be considered negligible. Additionally, They’ll give 100$ free credit to students (Interestingly, They also accept students from Iran). Fortunately, credit card is not required.
-
DigitalOcean Spaces (Non free): DigitialOceon also offers S3 compatible cloud storage. Although their service doesn’t have free credits, their prices are pretty low and cost beneficient (5$ / mo).
-
IBM Cloud Object Storage (Almost Free): I haven’t used it myself. Nevertheless, they have S3 compatible cloud storage and give you 200$ free credit on sign-up (it is conditioned to a valid credit card).
If you use the cloud storage carelessly, you could run out of money really fast. Don’t hesitate to delete the useless files, specifically the model checkpoints.
Apparently, PyTorch doesn’t support writing the checkpoint file to cloud. To overcome this issue, let PyTorch save them on the local disk, and then fire up a script to sync the checkpoint to the cloud storage.
Summary
The focus of this article was on the first two parts of the pipeline. Thank you for staying with me to end of this article. I will explain the third one (the most important one) in part two. Nonetheless, please drop me a line at the comment section if you have any issues with this part.